
上萬圖層也不卡頓:Figma 重寫圖層面板的兩個關鍵修法
七年前寫的圖層面板開始卡。Figma 用兩段式計算與衍生屬性快取砍掉重練,最大最複雜的檔案互動快了 30-50%——而且不只面板,整個編輯器都跟著順。


你可能沒注意過圖層面板(layers panel),但你每天都在用它。左側那條巢狀的清單,是一個 Figma 檔案的藍圖——所有 frame、群組、元件、文字,全攤在那裡。
問題是,這個面板是將近七年前寫的,那時候的檔案小、功能少。七年後,一個檔案裡塞上萬個圖層已經是日常。於是它開始卡:展開一個群組要等、拖拉物件會頓、連打字都慢半拍。Figma 工程團隊乾脆把它砍掉重練,結果是在最大、最複雜的檔案裡,互動快了 30 到 50%。
先講清楚這個面板在做什麼。Figma 檔案本質上是一棵節點樹(tree of nodes),結構跟 HTML 很像:每個節點有自己的屬性(名稱、是否可見等),底下掛著一串子節點。要把這棵樹畫成左側那條清單,Figma 得組出一個龐大的 JavaScript 物件,裝進每個節點的所有資料。
舊做法是「一趟掃完」:從當前頁面的每個頂層節點出發,收集它的資料;如果它是展開的,就遞迴鑽進子節點,再收集、再鑽進去。檔案一大、展開的節點一多,這趟掃描就重得離譜——而且每次面板有任何變動,整件事就重來一次。
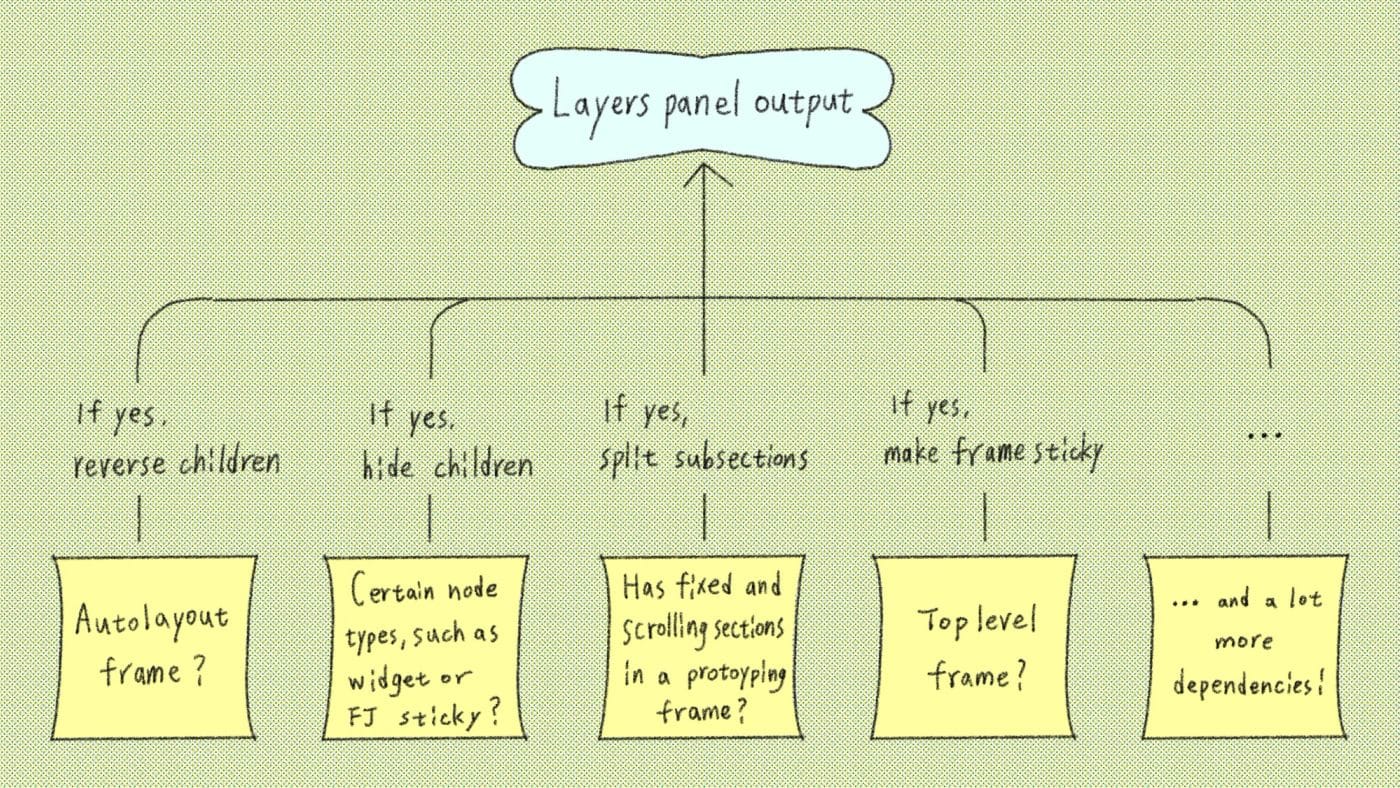
要治「算太多」,團隊把收集資料的過程拆成兩趟。
第一趟,只算出「面板上該出現哪幾列、順序是什麼」這一份 row ID 清單,其他資料先全部擱著。別小看這份清單——光是排序就一堆眉角:autolayout frame 的子層要反序顯示、widget 跟 FigJam 便利貼不顯示子層、原型 frame 的固定與捲動區段要拆成兩塊、頂層 frame 要 sticky 釘住。
第二趟才去算每一列真正要顯示的東西:名稱、圖示、鎖定狀態、可見性、選取狀態。關鍵在於,有了第一趟的 ID 清單,第二趟只需要替「視窗內」那幾十列算資料。這個技巧叫 windowing(視窗化)——捲動清單只渲染螢幕上看得到的項目。舊架構其實也有 windowing,但因為全擠在一趟算,連看不到、根本不渲染的列也照算不誤。
治「算太頻繁」,靠的是 Figma 這幾年累積的底層機制:衍生屬性(derived properties)。
道理跟試算表很像。節點有些值是直接存的(像相對位置),有些值則是「從別的值算出來的」。例如一個節點的絕對位置,Figma 不直接存,而是用「父層絕對位置 + 自己的相對位置」現算——這樣移動或旋轉一整群物件才方便。衍生屬性把這種「A 由 B、C 算出來」的關係正式宣告出來,系統就會自動追蹤相依、需要時才重算,跟試算表裡一格公式引用其他格一模一樣。
套到圖層面板上,好處立刻浮現:以前樹裡任何地方一變,整棵樹重算;現在每個節點都知道自己依賴誰,只有「真的受影響的那一小段」需要更新。展開 Frame B,就只重算 A 到 B 這條路徑,旁邊 Frame C 底下那 100 個子層完全跳過。再加上衍生屬性預設「懶算」(lazy)——沒被展開、沒人讀取,它就永遠不算。
快取一定會吃記憶體。小幅增加換來大幅提速,划算;但吃過頭就會冒出「記憶體不足」的錯誤,那種體驗很折磨人。
問題出在天真的快取寫法:每一層都把底下所有後代的 ID 存一份,記憶體成本會像三角數一樣累加(1 + 2 + … + n,等於 n(n+1)/2),也就是 O(n²)。在很深的樹裡,這可能膨脹到數十 MB,不能接受。
團隊改用一種類似 rope 的遞迴結構來存這份排序清單。rope 是把序列拆成小片段的樹狀結構,編輯或串接時可以重用既有片段,不必整串重建。關鍵在於它用指標(pointer)組合、而非整份複製,最大化「結構共享」。代價只是讀取時要多走幾步指標,換來記憶體用量從 O(n²) 降到嚴格的 O(n)——比最初原型省下最多 99% 記憶體。
兩招下來,效益很明確。展開/收合列、切換可見性或鎖定這類核心互動,在最大、最複雜的檔案裡快了將近 30 到 50%。
更有意思的是漣漪效應。圖層面板省下的不必要運算,回饋到整個 Figma 編輯器——整體渲染變順、FPS 提高、卡頓的影格變少。於是那些原本「在複雜檔案裡明顯黏滯」的動作,像打字、拖拉、選顏色,現在都穩定流暢了。一個藏在側邊欄的元件,優化得當,居然能讓整個畫布跟著呼吸順暢。
這篇拆的是工程細節,但底層的兩個原則,任何天天開大檔案的人都用得上:只做「看得到的部分」的工,只重算「真的變了的那塊」。windowing 對應的是收合不看的圖層,衍生屬性對應的是用乾淨結構讓工具知道誰依賴誰。工具在底層替你省力,你在上層把檔案整理乾淨,兩邊才會合拍。