
PGKeeper 上線:Figma 為什麼自己刻一個資料庫看門員,從 PgBouncer 換掉的工程決策
Figma 用 Go 寫 PGKeeper 取代 PgBouncer——admission control 的 priority semaphore + CoDel + fair sharing 樹、連線管理三件套、3× peak 壓測 + 自動 flip back 的 rollout 路徑。設計師讀完會發現:每個工程 tradeoff,在 design system 都有對應版本。


你打開 Figma 文件那一秒,畫布跑出來、最近編輯記錄秒讀、留言 dot 同時亮起。這些動作背後是同一條路徑——應用層問 PostgreSQL 要資料、PostgreSQL 回。
中間擋著的這層叫 connection pooler。它存在的目的很單純:每個連線在 Postgres 上是獨立 process,建立一次很貴,爆量一次資料庫直接被拖垮。pooler 把連線復用、把流量塑形,是 Figma 後端最低調但最關鍵的一塊。
Figma 過去用的是業界最常見的 PgBouncer。這篇文章是 storage 團隊宣布他們把 PgBouncer 換掉了——換成自己用 Go 寫的 PGKeeper。從決定要換、到完整 rollout,他們公開了一份很值得讀的工程紀錄:怎麼評估、怎麼刻、怎麼安全地把 production 流量切過去。
- 01PgBouncer 的天花板:為什麼夠用變不夠用
- 02自建 vs 改現成:Figma 為什麼選自己寫
- 03連線管理:把連線當資產護住
- 04Admission control:流量塞爆時誰先過
- 05安全 rollout:怎麼把流量無痛切過去
- 06整體觀察:工程決策也是設計決策
Figma 過去幾年產品線拓得很開——Make、Weave、FigJam、Slides、Sites 一個接一個上線。每多一個產品,資料庫層的負載就多一份。Storage 團隊先是把 Postgres 做了水平 sharding 跟 vertical sharding,再用一個叫 DBProxy 的 query router 把分片邏輯藏在 application code 之外。
DBProxy 後面接的,就是這篇文章主角的位置——connection pooler。每台 Postgres 機器配一組 pooler replica,n 對 1 的關係。這層的工作很乾脆:把 application 來的請求轉成一個個 Postgres connection,盡量復用、盡量別讓資料庫處理大量短連線。
PgBouncer 是業界用了十幾年的標準解。Figma 早期跑得也很順。問題是流量等級拉到一個量級之後,原本可以接受的設計選擇變成了硬天花板。
第一個是擴展性。PgBouncer 是單執行緒架構,垂直擴展頂多到一個程度。團隊試過用更多 replica 水平擴出去,結果 load distribution 不均,效能反而衰退。第二個是 load management。PgBouncer 沒有優先級概念,也沒有 backpressure 機制;當流量爆衝(突發從 20K QPS 跳到 45K QPS),critical 的使用者請求跟低優先級的批次工作排同一條 queue,沒辦法分流。第三個是連線管理。Postgres 連線本來就是 process-per-connection,建立成本高;PgBouncer 沒有節流機制,一場 incident 後的恢復過程,本身會造成第二波 churn 把 Postgres 再壓垮一次。第四個是可延伸性。要把 observability、feature flag、admission control 這些 infrastructure 標配加上去,得改 PgBouncer 的核心 code path——團隊算過,這條路的長期維護成本太高。
自建之前,團隊先排除了兩條路。
第一條是把 connection pooling 做到 DBProxy 裡。看似省事,數字對不上——Postgres 一台 instance 大約配 100 條連線,但 DBProxy 是 stateless、有上百個 replica。要把 100 個有限資源切給上百個 replica,要嘛超發、要嘛得跨 replica 做複雜協調,兩個都不可行。
第二條是用社群現成的 PGCat。PGCat 是 multi-threaded 的 Go 實作,剛好補上 PgBouncer 垂直擴展的缺。問題是 observability、feature flag、admission control 一樣得深度改 core,這些改動上游不會收,等於要長期維護一支 fork——跟改 PgBouncer 同一個坑。
剩下一條路就是自己寫。PGKeeper 是一個 Go service,建在 PGX 這套成熟的 Postgres toolkit 上。它對外用 gRPC,每筆 query 帶著 metadata(traffic tier、user type、來源),讓 server 端可以看著訊號做決策。位置上,它接在 DBProxy 跟 Postgres 之間,每個 PGKeeper 替一台 Postgres 服務、每個 instance 配多個 replica 跨 Kubernetes cluster 做高可用。
Option A — Fork PGCat
對外能講「我們用社群方案」,對內得長期維護一支 fork。每次 upstream 改、自己也得追,自己加的 observability / feature flag 還要不斷重新合併。
Option B — 自己刻 PGKeeper
從 PGX 開始疊,第一天就把 observability、feature flag、admission control 設計進核心 code path。三個都不會被 fork 維護成本卡住。
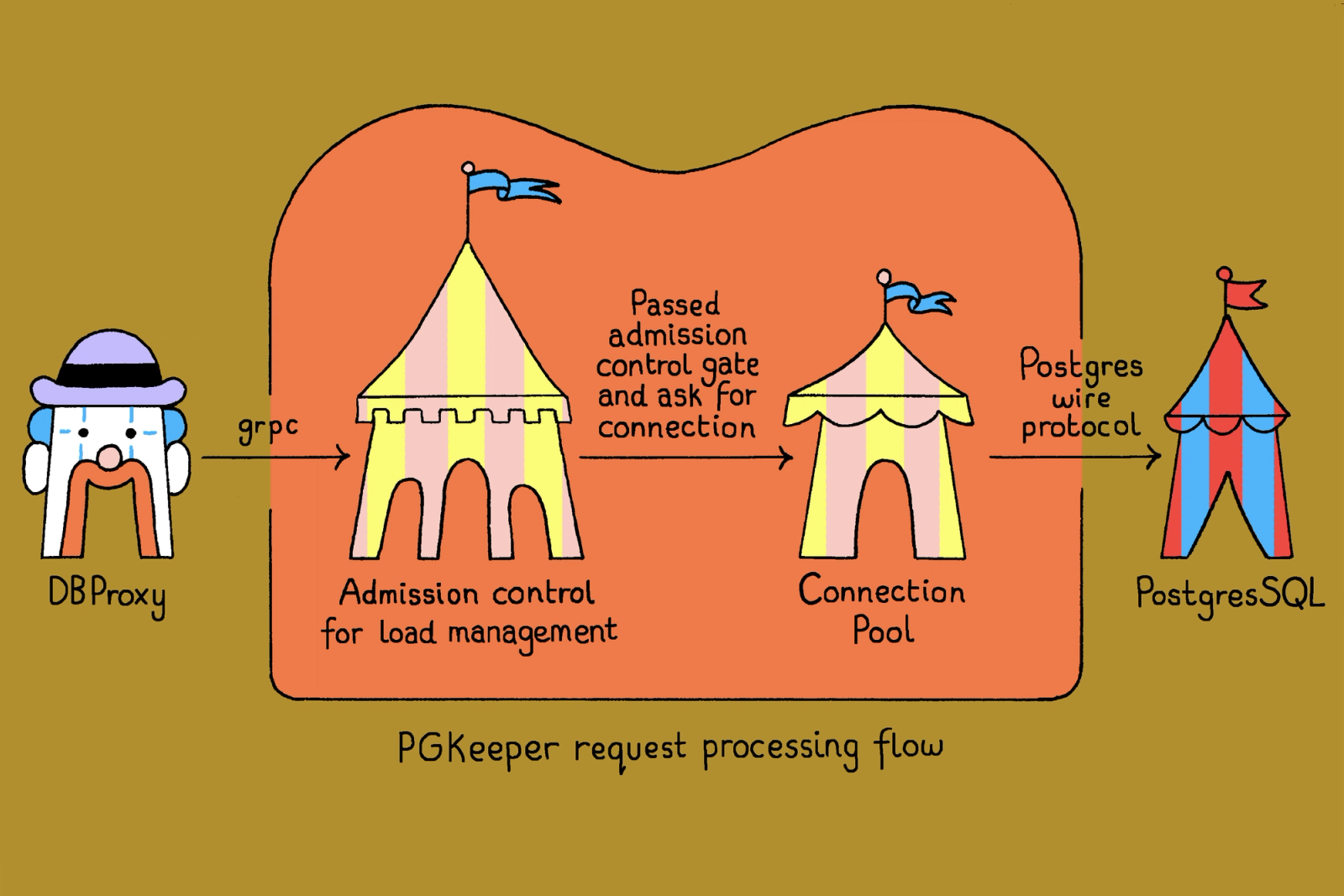
每筆請求進到 PGKeeper 會走三個階段——admission control、connection pool、query execution。最有看頭的是中間這層 connection pool,因為 Postgres 連線本身就是貴的東西。
第一個機制是 pool warming。新的 PGKeeper 起來時連線池是空的,第一波請求得邊建連線邊處理,延遲飆很高。Pool warming 在 production 流量還沒進來之前,就先把連線預先建好,把這段熱機時間移到使用者看不見的地方。
第二個機制是建立跟拆除都做 rate limit。Pool warming 解的是穩態,但一旦遇到大規模 churn,重建連線本身就會把 Postgres 壓垮。PGKeeper 用 token bucket 把建立速度節流。拆除也一樣——團隊在 PostgreSQL 13.21 升 13.22 的時候才發現,pool shutdown 那一波關閉連線會讓資料庫 CPU 飽和,所以拆除這側也加上節流。
剩下三個都是「讓連線可以乾淨還回去」的細節。Bounded exhaust:client 沒讀完整個 result set 時,連線會殘留 server-side state,PGKeeper 會主動 drain 最多 100 row(P99 query 回傳少於 5 row,這 100 個閾值已經夠 cover 大多數)。Auto rollback:連線釋放時還在 transaction 中,自動先 ROLLBACK 再放回 pool。Context cancellation:client 取消請求時,PGKeeper 立刻回空結果給 caller,背景再走 pg_cancel_backend,跑一條 SELECT 1 把 kill signal flush 掉,最後這條連線才回到 pool。連 cancel 用的連線都另外開一個獨立 pool,避免 cancel 把主 pool 占用掉。
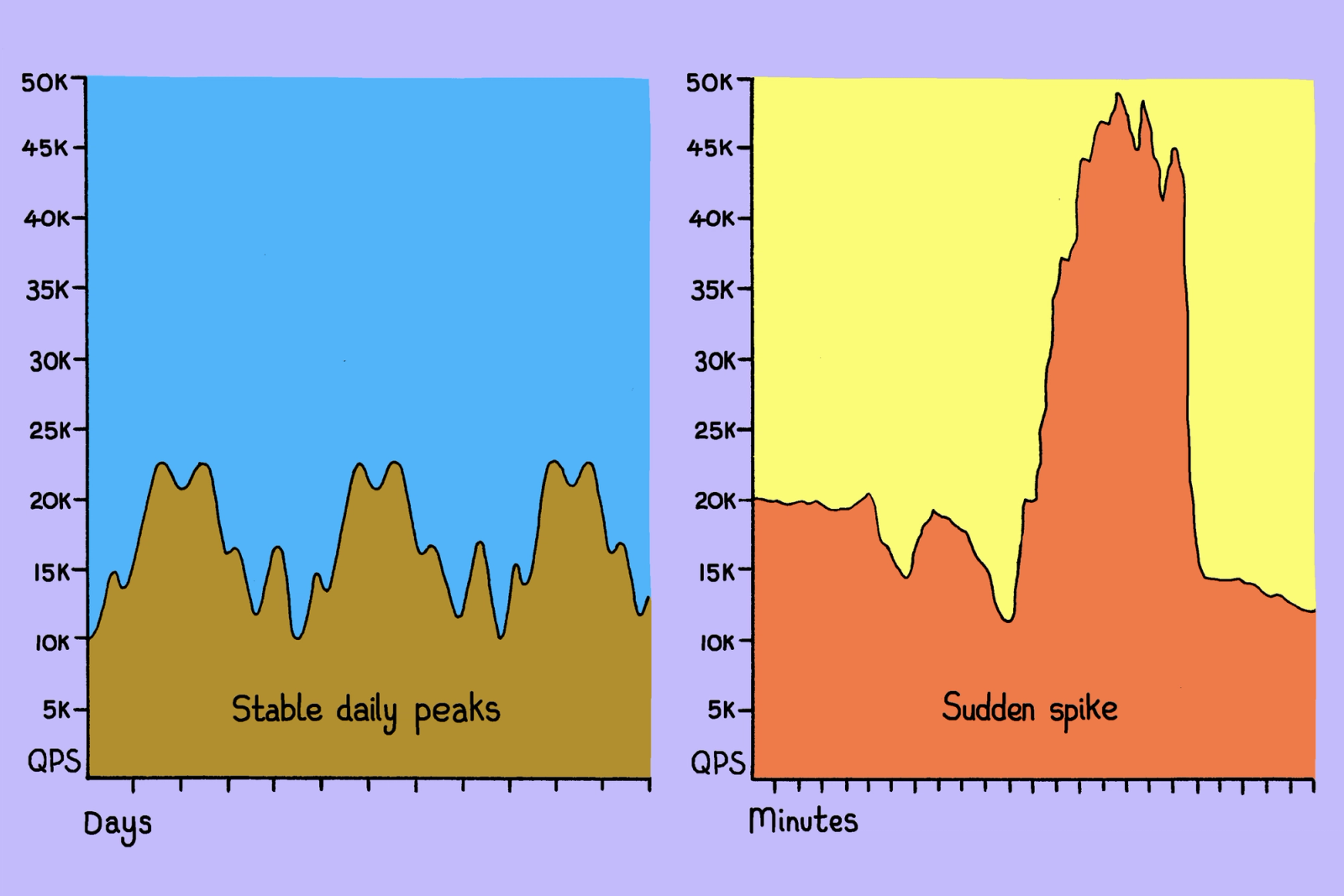
超過容量時,請求一定要丟掉一些。問題是丟哪一筆。
V1 的設計是 priority semaphore + CoDel + adaptive LIFO + debt 機制。每個請求都帶著 priority,高優先級對應 critical 的使用者操作(開檔、存檔),低優先級對應背景任務。當高優先級拿不到 ticket,系統會給所有低優先級 tier 累積「debt」——債要還掉,低優先級才能再進來。Debt 會隨時間衰減,高優先級恢復順暢時還得更快。Queue 健康時走 FIFO,當 queue 持續累積、變得不健康,自動切成 LIFO 並縮短可等時間,把卡死的舊請求先丟掉、保住新請求。
V1 上 production 之後團隊發現一個漏洞——同一個 priority tier 內部還是會有單一工作載量把容量吃光。一個爆紅功能、一場 DDoS,都可能把高優先級預算耗盡,連累同 tier 其他無關工作。
V2 加了一層 weighted min-max fair sharing。Traffic 的維度被組成樹——第一層按認證狀態分流(有登入的權重高很多),第二層再按 endpoint 路由。容量從根節點往下遞迴分配,每個節點按權重切給子節點。沒用滿的份額會回到 pool 給需要更多的人——沒人會餓死、也沒人能獨吞。一筆請求要先過 priority admission control、再過 fair sharing,兩道都點頭才放行。
進入 admission control
優先級 semaphore 先看高優先級有沒有空缺;沒空缺就讓低 tier 累積 debt。
切到 LIFO + CoDel
Queue 持續滿載 → 切 LIFO + 縮短等待 → 老的請求先丟、新請求先過。
過 fair sharing 樹
按認證狀態 × 路由分維度切容量;同 tier 不同 endpoint 也不會互相搶死。
Client 反向退讓
PGKeeper 回特定 error code,client 端的 AdaptiveThrottle 接到後做 exponential backoff,server 跟 client 自然收斂到穩定速率。
把流量從一個 pooler 切到另一個 pooler 而不出事,本身就是一場工程任務。團隊分四步走。
第一步是 Disaster Readiness Testing。Load test 把 PGKeeper 推到 3 倍 production peak QPS——測它撐不撐得住,也量 gRPC 多塞的延遲是多少。結果是 sub-millisecond 的開銷,換來 load management 跟 observability 的能力,划算。Synthetic load 是另一條——團隊把過去害過自己的 incident 流量重新生成出來,一場場放給 PGKeeper 試,調參數調到每一場都過得去。
第二步是分級 rollout,把 blast radius 鎖小。每組資料庫先按關鍵性分級,從風險最低的開始。先在每個 cluster 上一台 replica(DBProxy 會 hedging,掛了還有 PgBouncer 接),確認沒事再擴到全部 replica,然後是非關鍵的 primary,最後才動到關鍵 primary。
第三步是自動偵測。團隊在 DBProxy 上做了 sliding window error detector,連續幾個 window 錯誤率破門檻,DBProxy 會自動把流量切回 PgBouncer。這套機制在 rollout 初期觸發過幾次——每次都把 incident 控制在「短暫不可用」這個範圍內,比一個壞掉的 PGKeeper 繼續服務流量好得多。
第四步沒有寫在標題裡,但藏在每一步背後——可以隨時切回去的能力。Rollback path 不是事後想辦法,是 day 0 就設計進來。
讀這篇文章最有意思的地方,是 storage 團隊在每個分岔點都揭露了 tradeoff——擴展性換複雜度、靈活性換 fork 維護、CoDel 換 LIFO 切換邏輯、fair sharing 換實作成本。每一刀切下去都不是免費的。
這跟設計師的日常完全相通。Component variant 數量多寡、design token 顆粒度大小、Auto Layout 巢狀深度、prototype interaction 的複雜度——每個選擇背後都壓著「現在好用 vs 三年後好維護」「彈性 vs 一致性」「酷炫 vs 跨團隊溝通成本」。PGKeeper 的故事把這些 tradeoff 攤在工程語言裡講一遍,但底層思考方式跟你在 Figma 做 design system 決策時是同一套。
讓 Figma 在你電腦上順順跑的那層基礎設施,每天承受的決策密度跟你的設計檔一樣高——只是你看不到。